提供者:刘晓
地址:http://kdd.ics.uci.edu/databases/synthetic/synthetic.html
简介
该数据集旨在测试时间序列数据库中的索引方案。数据显示高度周期性,但从未完全重复。此功能旨在挑战索引任务。
数据集描述
数据类型
数据是一个合成的单变量时间序列。
数据特征
该数据集旨在测试时间序列数据库中的索引方案。这是一个比任何已发表的研究中都使用的数据集要大得多的数据集(我们目前知道)。它包含一百万个数据点。数据被分成10个部分以便于测试(见下文)。我们建议使用10万个数据点部分中的9个构建索引,并从第10部分中随机提取查询形状。 (一些以前发布的工作似乎使用了也用于构建索引结构的查询,这会产生乐观的结果)数据很有趣,因为它们具有不同分辨率的结构。通过独立调用函数生成的10个部分中的每一部分:
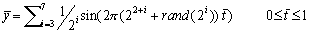
rand(x)产生零和x之间的随机整数。
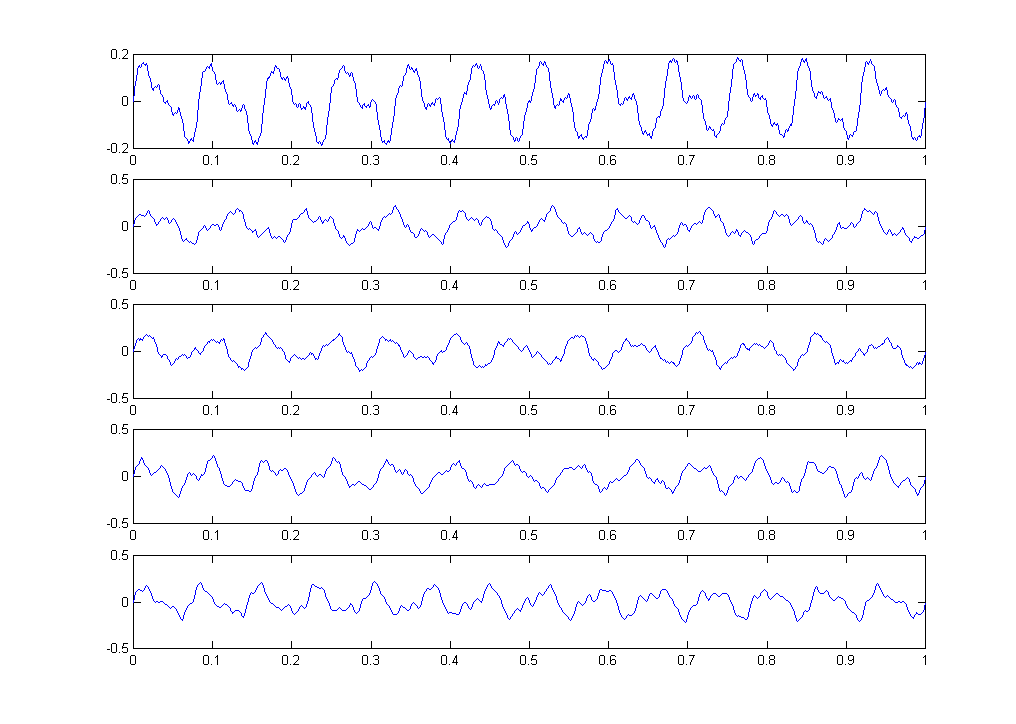
数据显示高度周期性,但从未完全重复。此功能旨在挑战索引结构。时间序列如下图所示:

数据格式
数据存储在一个ASCII文件中。有10列,10万行。所有的数据点都在-0.5到+0.5的范围内。 行由回车,空格分隔。
数据集下载
synthetic.data.gz (5.0M; 16.2M uncompressed)
相关论文
[1] Eamonn J. Keogh, Michael J. Pazzani: (1999). An indexing scheme for similarity search in large time series databases. The 11th International Conference on Scientific and Statistical Database Management. Cleveland, Ohio.
[2] L Yang,D Neagu. A New Approach and Its Applications for Time Series Analysis and Prediction Based on Moving Average of n th -Order Difference. 2012.
[3] S Basterrech,G Rubino,V Snášel. Sensitivity analysis of echo state networks for forecasting pseudo-periodic time series. 2016.
[4] M Small,RG Harrison,CK Tse. A Surrogate Test for Pseudo‐periodic Time Series Data. 2002.